> Small Language Models: How to Choose, Run, and Fine-Tune Them (2025–2026)

In 2019, GPT-2 launched with 1.5 billion parameters and the AI community called it large. Today, a 3B model is considered small. That compression (six years, two orders of magnitude) is the real story of where AI is heading.
MIT Technology Review put small language models on its Breakthrough Technologies list for 2025. Not because they're novel. Because they crossed a threshold, for the tasks most businesses actually need, a well-chosen SLM running on a laptop now matches or beats the cloud APIs that cost thousands of dollars a day. That changes what's practical to build.
This guide covers what SLMs are, how they're built, which ones are worth your attention in 2025–2026, and how to actually run and fine-tune them. No hype. Just what you need to make a good decision.
What Are Small Language Models?
SLMs are neural networks built for natural language tasks that can run on hardware you already own. The parameter range that qualifies as "small" is roughly 1 million to 10 billion, though that ceiling keeps creeping up as researchers squeeze more capability out of fewer parameters.
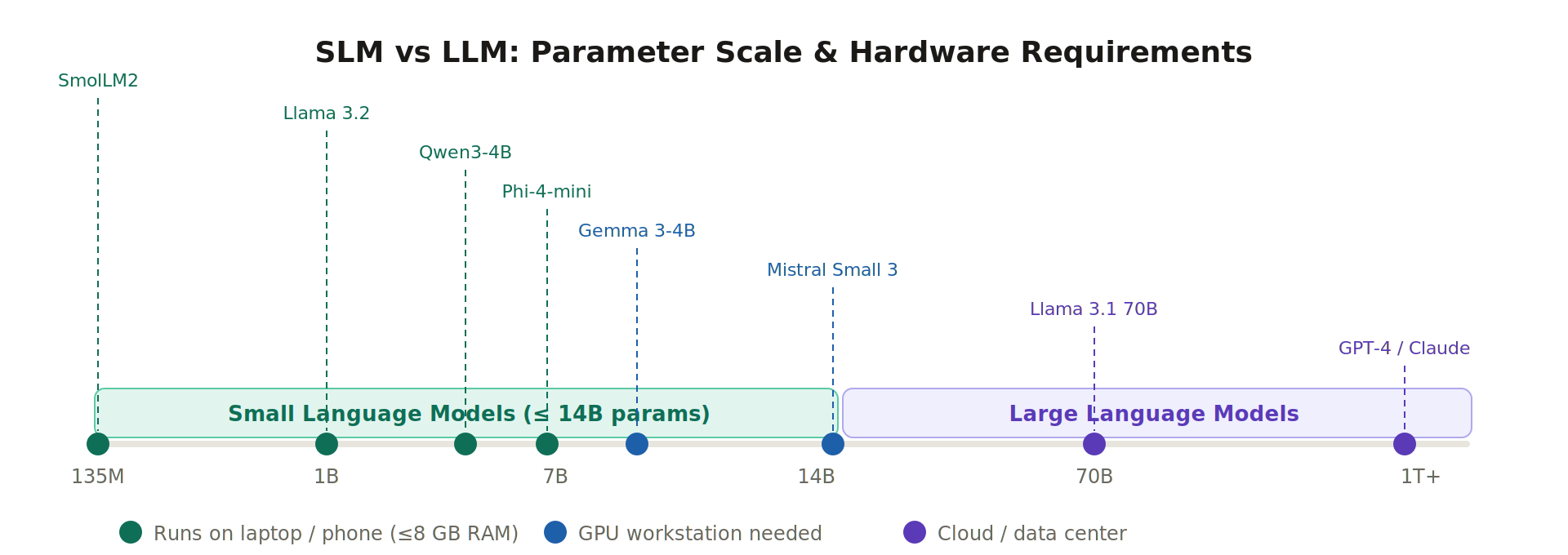
The "small" label is relative and a little misleading. GPT-2's 1.5 billion parameters made it a research landmark in 2019. Today you'd run it on a Raspberry Pi. What the category really means is runs on a machine you own, without a cloud API, without a GPU cluster. That's the meaningful boundary.
SLMs can do most of what LLMs do such as text generation, Q&A, summarization, translation, code completion. What they give up is reasoning depth on genuinely hard multi-step problems, and breadth of knowledge across obscure topics. For most production use cases, those gaps don't matter.
The key shift in 2025: Specialized SLMs now routinely outperform larger general-purpose models on the specific tasks they're fine-tuned for. If you're building a document classifier or a code assistant that does one thing well, a 4B SLM fine-tuned for your domain will beat GPT-4o-level models on your evals, at a fraction of the price to serve.
Benefits of Small Language Models
Speed and cost: these two get underrated
A 3B model generates around 50 tokens per second on a modern laptop. A 70B model on the same hardware does about 5. That 10x difference matters a lot for interactive applications where users wait for responses. And Mistral Small 3 (24B) now runs three times faster than LLaMA 3.3 70B while matching its output quality on most general tasks, which makes the "small" vs "large" frame increasingly fuzzy.
The cost angle is even more significant at scale. Running a 7B model locally eliminates per-query API fees entirely. A company processing a million queries a day at typical API rates, where a single query averages 300–500 tokens, is spending hundreds to thousands of dollars daily on cloud APIs for a task that a local SLM can handle for the price of the electricity.
Privacy
This one matters more than it gets credit for in benchmarking articles. On-device means no data leaving your machine. Healthcare, legal, finance: these domains have real regulatory constraints on where data can go. An SLM running locally isn't a workaround, for many use cases it's the only compliant option.
Customization is faster than most people expect
Fine-tuning a 3B model on domain data typically takes a few hours on a single consumer GPU. You don't need a multi-GPU cluster and you don't need a data science team. The gap between "generic base model" and "model that knows your product's terminology and always returns JSON in your schema" is now a weekend project.
Limitations of Small Language Models
The limitations are real and worth being specific about rather than vague.
Multi-step reasoning is still the ceiling. If your task requires a model to hold 15 intermediate steps in context and check its own work, a 3B model will make errors a 70B model wouldn't. MIT CSAIL's DisCIPL system (December 2025) worked around this by using an LLM for planning and routing subtasks to multiple SLMs in parallel, beating GPT-4o on constrained reasoning benchmarks. Worth watching, but not production-ready for most teams.
Knowledge breadth is narrow. SLMs don't know what they weren't trained on, and their smaller capacity means they store less of the world. For anything involving recent events, niche domains, or obscure facts, RAG (retrieval-augmented generation) is not optional. It's how you make SLMs usable for knowledge-intensive tasks.
Prompt sensitivity. Small models are less robust to rewording. A prompt that works perfectly can break with minor variation. This is less of a problem if you're building a focused application with controlled inputs, but it matters a lot if you're building a general assistant. Expect to spend time on prompt engineering that you wouldn't need with a frontier model.
Context windows are catching up. Phi-4-mini and SmolLM3 support 128K tokens. Qwen3.5-0.8B supports 262K tokens at under 1B parameters. This was a genuine limitation two years ago, it's much less of one now.
How SLMs Are Built
There are four main approaches. Modern SLMs often combine several simultaneously.

Knowledge Distillation
The teacher-student setup: a large model (the teacher) generates outputs including its full probability distributions across tokens, not just the top prediction. A smaller student model trains on those distributions, learning the teacher's reasoning patterns instead of just mimicking final answers. It's the difference between copying someone's essay and sitting next to them while they write it.
DeepSeek-R1-Distill uses this. So does Phi-4-Mini-Reasoning, which in 2025 combined distillation with reinforcement learning to produce a 3.8B model that outperforms the 7B DeepSeek-R1-Distill on MATH-500. The student beat a bigger model trained the conventional way.
Pruning
Not every parameter in a trained model contributes equally. Many weights hover near zero and can be removed without measurable quality loss. Structured pruning eliminates entire neurons, attention heads, or layers. Unstructured pruning removes individual weights. Either way, you end up with a sparser network that needs less memory and runs faster.
The 2025 MiniLM release combined adaptive pruning with quantization and matched large model accuracy at under 5% of the compute.
Quantization
This is the most practical technique for anyone running models locally. Training uses 32-bit floating-point numbers. Most inference defaults to 16-bit. But you can go further like to 8-bit, 4-bit. A 7B model that needs 14 GB of VRAM at FP16 drops to 3.5 GB at INT4. Same model, fits on a gaming GPU instead of a server rack.
| Precision | Memory (7B model) | Notes |
|---|---|---|
| FP32 | 28 GB | Training standard |
| FP16 | 14 GB | Inference default |
| INT8 | 7 GB | Minor quality loss |
| INT4 | 3.5 GB | Production standard in 2025 |
Q4_K_M, the quantization format used in llama.cpp and Ollama, has become the default for everyday use. It sits at a quality-to-size tradeoff most people can't detect in practice. Start there before going lower.
Training From Scratch on Quality Data
Microsoft's Phi series and Hugging Face's SmolLM3 skip distillation entirely. They train from scratch, but on carefully curated data, FineWeb-Edu, DCLM, The Stack. The bet is that a small model trained on high-quality educational content learns more efficiently than a large model trained on internet noise.
The benchmarks backed them up. Phi-4-mini at 3.8B matches or beats models twice its size on reasoning tasks. Data curation turned out to matter more than scale, at least below 10B parameters.
Notable Models (2025–2026)
The table below covers the models worth knowing. Three things changed dramatically since 2024, multimodal capability at small scale went from rare to table stakes, reasoning chains got successfully distilled into sub-7B models, and context windows expanded to 128K even at 3B parameters.
| Model | Params | Developer | What's new / strengths |
|---|---|---|---|
| Qwen3 | 0.6B, 1.7B, 4B, 8B | Alibaba | Thinking + non-thinking modes; 200+ language support; strong reasoning at 4B |
| Qwen3.5 | 0.8B | Alibaba | Multimodal (text, image, video); 201 language support; Apache 2.0 |
| Phi-4-mini | 3.8B | Microsoft | 128K context; 20+ languages; matches 7–9B models on benchmarks; MIT license |
| Phi-4-mini-Reasoning | 3.8B | Microsoft | Outperforms DeepSeek-R1-Distill-7B on MATH-500; CoT distillation + RL |
| SmolLM3 | 3B | Hugging Face | Fully open (Apache 2.0 + full training blueprint); 128K context; dual reasoning mode |
| Gemma 3 | 270M – 12B | Vision + text at 4B; 128K context; 270M version is genuinely tiny | |
| Mistral Small 3 | 24B | Mistral AI | Matches LLaMA 3.3 70B quality; runs 3× faster; 24B is pushing the "small" definition |
| Llama 3.2 | 1B, 3B | Meta | NPU-optimized for mobile; tool calling built in; the on-device default |
| DeepSeek-R1-Distill | 1.5B, 7B | DeepSeek | Distilled from R1; strong chain-of-thought; 1.5B is surprisingly capable |
| Ministral-3B | 3.4B + 0.4B vision | Mistral AI | Multimodal; 8 GB VRAM in FP8; edge + vision in one model |
| SmolLM2 | 135M, 360M, 1.7B | Hugging Face | 135M runs in a browser tab; 360M runs on Raspberry Pi |
One pick if you're starting out on a standard developer laptop: Phi-4-mini. It runs in 8 GB RAM at Q4_K_M, handles 128K contexts, and its reasoning quality is genuinely impressive for 3.8B parameters. Pull it with ollama pull phi4-mini and you're running in two minutes.
Real-World Applications

On-Device Assistants
Llama 3.2-3B running locally drafts emails, answers questions, summarizes documents, no network connection needed. PocketPal AI on iOS and Android makes this straightforward, download the model once, run offline indefinitely. For enterprise use cases where data locality matters, this is the deployment pattern.
Code Completion
Phi-4-mini at Q4_K_M quantization uses around 2.8 GB VRAM. That leaves 5+ GB free for your IDE, browser, Docker containers, whatever else you're running. Local code completion means no code leaves your machine, which matters if you're working in a codebase with IP sensitivity. Qwen2.5-Coder-7B is the stronger pick for pure code generation, Gemma 3-4B handles the full workflow (completion, explanation, documentation) more consistently.
Document Processing
128K context means you can load an entire report (most corporate PDFs) in a single prompt. Ask questions about it, summarize sections, extract structured data. SLMs handle this well on standard business hardware without any cloud dependency.
Industrial Edge AI
In 2025, Microsoft's AI model catalog partners launched several notable domain-specific SLMs: Bayer's crop protection model, Cerence's offline in-car AI, Rockwell Automation's manufacturing assistant. These aren't generic models deployed to the cloud. They are fine-tuned SLMs running on-device in constrained environments. This is where specialized SLMs outperform general-purpose frontier models by a wide margin.
Healthcare
Clinical note processing and medication information lookups are good fits repeatable, structured outputs, strong data locality requirements. The fine-tuning + local deployment combination addresses both the domain knowledge gap and the regulatory requirement. This is an area where a 7B fine-tuned SLM will beat a generic 70B model on your specific tasks.
Fine-Tuning Small Language Models

LoRA (Low-Rank Adaptation)
LoRA freezes the base model's weights and adds small trainable adapter matrices. You update roughly 0.1% of the total parameters: enough to shift model behavior significantly, not enough to require serious compute. An afternoon's training on a single consumer GPU is realistic for domain adaptation.
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("microsoft/phi-4-mini-instruct")
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none"
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# trainable params: 4,194,304 || all params: 3,825,598,464 || trainable%: 0.11
QLoRA
QLoRA loads the base model in 4-bit precision, then adds LoRA adapters on top. Fine-tuning a 7B model fits in 8 GB VRAM. This opened up model customization to anyone with a gaming GPU.
from transformers import BitsAndBytesConfig
from peft import LoraConfig, get_peft_model
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4"
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=quantization_config,
device_map="auto"
)
model = get_peft_model(model, lora_config)
The Synthetic Data Pattern
Use GPT-4o or Claude to generate a high-quality instruction dataset for your domain. Then fine-tune a 4B SLM on that dataset. You pay for the data generation once, you serve the specialized SLM indefinitely at local inference cost. This pattern became common in 2025 because it works. The SLM learns the task structure from high-quality examples, not from raw internet text.
When Fine-Tuning Is Worth It
Fine-tune when, the base model doesn't know your domain's terminology, you need consistent structured outputs (JSON schema, specific formats), or general prompting hits a ceiling on your evals.
Skip fine-tuning when, good prompting gets you 90% of the way there, you need the model to generalize across many different tasks, or your use case changes frequently enough that a static fine-tune becomes stale.
Choosing the Right Model
Start with the smallest model that passes your quality threshold. Running evals on your actual use case matters more than benchmark comparisons. Benchmark performance and real-world performance on specific tasks diverge more than people expect.
| Use case | Recommended | Why |
|---|---|---|
| Ultra-portable (Pi, browser, IoT) | SmolLM2-135M/360M, Qwen3-0.6B | Under 1 GB RAM; browser-deployable |
| Mobile (iPhone / Android) | Llama 3.2-1B/3B, Gemma 3-1B | NPU-optimized; offline capable |
| Laptop all-rounder | Phi-4-mini (3.8B), Qwen3-4B | 128K context; strong reasoning; 8 GB RAM |
| Math / science reasoning | Phi-4-mini-Reasoning, DeepSeek-R1-Distill-7B | Beat 7B peers on MATH-500; CoT distillation + RL |
| Coding (local IDE copilot) | Qwen2.5-Coder-7B, Gemma 3-4B | HumanEval-optimized; handles both tab completions and chat |
| Multilingual | Qwen3-4B (200+ langs), Phi-4-mini (20+ langs) | Strong non-English support |
| GPU workstation / near-LLM quality | Mistral Small 3 (24B), Qwen3-14B | 3× faster than 70B at comparable quality |
| Fully open / custom training | SmolLM3-3B | Apache 2.0 + full training blueprint published |
Test at Q4_K_M quantization. That's what you'll run in production, so that's what you should evaluate.
The Future of Small Language Models
The Gartner prediction that organizations will use task-specific SLMs three times more than general-purpose LLMs by 2027 seems plausible given where things are heading. A few developments worth watching:
Agentic SLMs are getting serious. Qwen3 and Jan-v1-4B are built with tool use and multi-step reasoning in mind at 3–4B scale. Running agents locally, without routing everything through an API, is now practical for many workflows.
Multimodal at small scale is table stakes. Gemma 3-4B, Ministral-3B, and Qwen3.5-0.8B handle vision. Qwen3.5-0.8B handles video. The argument that you need a large model for multimodal is gone below 1B parameters.
MIT CSAIL's collaborative inference idea is worth tracking. Their DisCIPL system (December 2025) uses an LLM for planning and routes subtasks to parallel SLMs, getting LLM-level accuracy on constrained reasoning tasks at a fraction of the energy cost. If that approach matures into a production pattern, it changes how you think about inference architecture.
NPU hardware is catching up with the software. Apple M-series chips, Qualcomm Snapdragon X, these have dedicated neural processing units that make on-device SLM inference genuinely fast. The hardware argument for cloud inference is weakening every product cycle.
The practical upshot, if you haven't run a local model yet, now is a good time to start. The install to first response time with Ollama is under five minutes, the hardware requirements are modest, and the gap between local and cloud quality on most real tasks is smaller than you'd expect.
References
- A Survey of Small Language Models (arXiv 2410.20011)
- Phi-4 Technical Report (arXiv 2412.08905)
- Phi-4-Mini-Reasoning (arXiv 2504.21233)
- SmolLM2 on Hugging Face Blog
- SmolLM3-3B on TinyWeights.dev
- Small Language Models: MIT Technology Review Breakthrough Technologies 2025
- MIT CSAIL DisCIPL: Collaborative SLM Reasoning
- Best Open-Source SLMs 2026 on BentoML
- Ollama
- PocketPal AI
Comments (0)
No comments yet. Be the first to comment!